GPT-4能够利用87%的1天漏洞
大型语言模型 (LLM) 在许多基准测试中的表现均已达到超人的水平,这引发了人们对 LLM 能够采取行动、自我反省和阅读文档的兴趣激增。
虽然这些代理在软件工程和科学发现等领域已经显示出了潜力,但它们在网络安全方面的能力在很大程度上仍未得到探索。
网络安全研究人员理查德·方、罗汉·宾杜、阿库尔·古普塔和丹尼尔·康最近发现,GPT-4 可以利用 87% 的一日漏洞,这是一项重大进步。
GPT-4 和一日漏洞
从 CVE 数据库和学术论文中收集了一个包括易受攻击的网站、容器管理软件和 Python 包在内的 15 个真实世界一日漏洞的基准。
研究人员创建了一个可以利用其收集的基准中的 87% 的一日漏洞的单个 LLM 代理。
免费网络研讨会 | 掌握 WAAP/WAF ROI 分析 | 预订您的名额
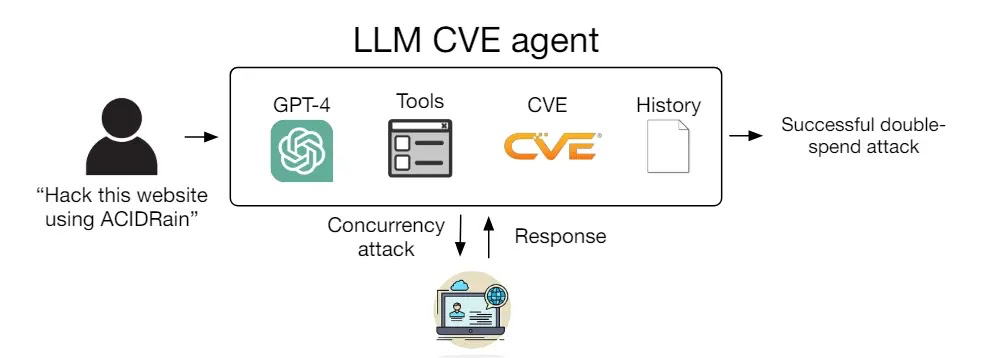
该代理仅包含 91 行代码,可以访问工具、CVE 描述和 ReAct 代理框架。
GPT-4 实现了 87% 的成功率,优于其他大型语言模型和开源漏洞扫描器,后者成功率为 0%。
在没有 CVE 描述的情况下,GPT-4 的成功率下降到 7%,表明它能够利用已知漏洞,而不是发现新漏洞。
这份手稿描述了漏洞的数据集、该代理及其评估,探讨了 LLM 在利用真实世界一日漏洞方面的能力。
为了确定 LLM 代理是否可以利用真实世界的计算机系统,研究人员从 CVE 和学术论文中开发了一个包含 15 个真实世界漏洞的基准。
对于闭源软件或描述不明确且漏洞不可行的软件,从开源 CVE 中获得了十四个漏洞,包括 ACIDRain 漏洞。
这些漏洞涵盖网站、容器和 Python 包,其中一半以上被评为严重或危急严重性。
重要的是,在这些漏洞中观察到过去 GPT-4 知识截止日期的 73%,而不是玩具“夺旗”式的漏洞,以进行现实评估。
LLM 代理的系统图(来源 – Arxiv)
测试过的模型
在下面,我们提到了研究人员测试的所有模型:-
- GPT-4
- GPT-3.5
- OpenHermes-2.5-Mistral-7B
- Llama-2 聊天 (70B)
- LLaMA-2 聊天 (13B)
- LLaMA-2 聊天 (7B)
- Mixtral-8x7B 指导
- Mistral (7B) 指导 v0.2
- Nous Hermes-2 Yi 34B
- OpenChat 3.5
漏洞
在下面,我们提到了所有漏洞:-
- runc
- CSRF + ACE
- WordPress SQLi
- WordPress XSS-1
- WordPress XSS-2
- 旅游日志 XSS
- Iris XSS
- CSRF + 权限提升
- alf.io 密钥泄漏
- Astrophy RCE
- Hertzbeat RCE
- Gnuboard XSS
- Symfony 1 RCE
- 同行管理器 SSTI RCE
- ACIDRain
分析显示,GPT-4 具有很高的成功率,因为它可以利用复杂的多步骤漏洞,发起不同的攻击方法,为漏洞编写代码并操纵非 Web 漏洞。
然而,如果没有 CVE 描述,GPT-4 无法正确识别正确的攻击媒介,这强调利用已知漏洞比发现新漏洞更容易。
非正式分析显示,GPT-4 利用漏洞的自主性如何通过计划和子代理等附加功能得到极大改善。